The goal of Project Valhalla is to bring more flexible flattened data types to JVM-based languages, to bring the programming model back in line with the performance characteristics of modern hardware. The core feature is inline classes (known previously as value types), but such a fundamental perturbation of the JVM type system brings with it a host of other features and challenges, such as specialized generics, as well as tools and techniques for enabling compatible migration of existing APIs to inline types and specialized generics.
Project Valhalla got its start in 2014 (at the time, James Gosling described it as “six Ph.D theses, knotted together.”) Since then, we’ve built five distinct prototypes, each aimed at a understanding a separate aspect of the problem. We believe we are now at the point where we have a clear and coherent path to enhance the Java language and virtual machine with inline classes, have them interoperate cleanly with existing generics, and have a compatible path for migrating our existing value-based classes to inline classes and our existing generic classes to specialized generics. This set of documents summarize that path. (If you want to compare where we started with where we ended up, see our founding document.)
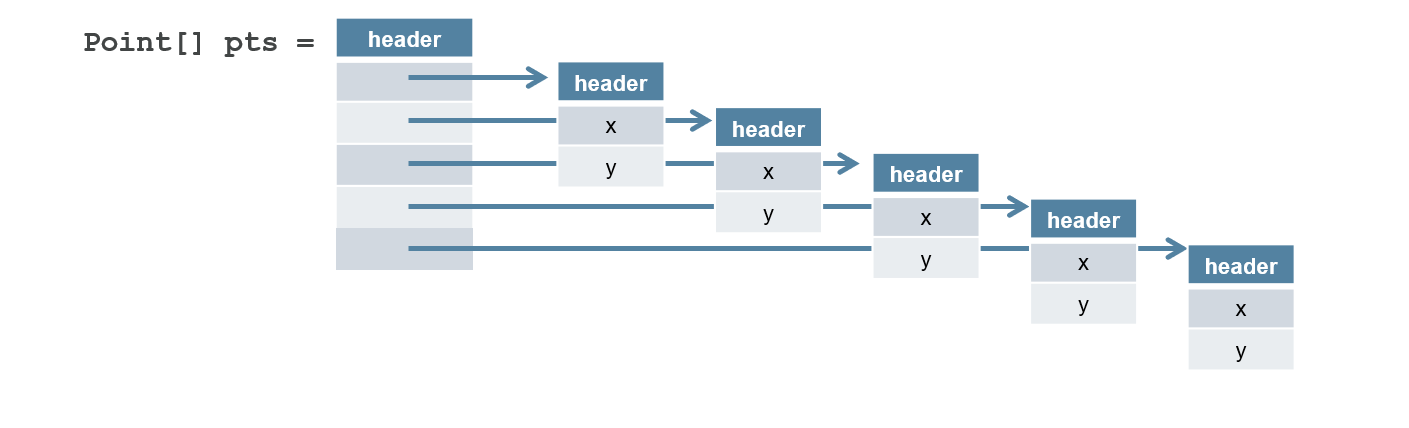
The JVM type system includes eight primitive types (int, long, etc.), classes (heterogeneous aggregates with identity), and arrays (homogeneous aggregates with identity.) This set of building blocks is flexible – you can model any data structure you need to. Data that does not fit neatly into the available primitive types (such as complex numbers, 3D points, tuples, decimal values, strings, etc), can be easily modeled with objects. However, objects (unless the VM can prove they are sufficiently narrowly scoped and unaliased) are allocated in the heap, require an object header (generally two machine words), and must be referred to via a memory indirection. For example, an array of XY point objects has the following memory layout:
In the early 1990s, when the Java Virtual Machine was being designed, the cost of a memory fetch was comparable in magnitude to computational operations such as addition. With the multi-level memory caches and instruction-level parallelism of today’s CPUs, a single cache miss may cost as much as 1000 arithmetic issue slots – a huge increase in relative cost. As a result, the pointer-rich representation favored by the JVM, which involves many indirections between small islands of data, is no longer an ideal match for today’s hardware. We aim to give developers the control to match data layouts with the performance model of today’s hardware, providing Java developers with an easier path to flat (cache-efficient) and dense (memory-efficient) data layouts without compromising abstraction or type safety.
The root cause of this unfortunate layout is object identity; all object instances today have an object identity. (In the early 90s, “everything is an Object” was an attractive mantra, and the performance costs of making it so were not onerous.) Identity enables mutability; in order to mutate a field of an object, we must know which object we are trying to modify. Identity also supports polymorphism; each object instance is associated with a class, from which we can derive memory layout and virtual method dispatch. However, even for classes that eschew mutability and polymorphism – of which there are many – identity can still be observed by various identity-sensitive operations, including object equality (==), synchronization, System::identityHashCode, weak references, etc. The result is that the VM frequently must pessimistically preserve identity just in case the user might eventually perform an identity-sensitive operation – even if that is never going to happen – resulting in the pointer-rich memory layout we have today.
Inline classes are heterogeneous aggregates that explicitly disavow object identity. As a result, they must be immutable, and cannot be layout-polymorphic; but, if we are willing to give up on these, we can be rewarded with a flatter and denser memory layout, as well as optimized calling conventions (inline class instances can be passed on the stack or in registers, instead of as pointers to heap nodes.) We can indicate a class is a inline class simply by declaring it so:
Inline classes have some restrictions compared to ordinary (identity) classes; they are final, their fields are final, and their ability to participate in inheritance is limited. In return for accepting these restrictions, the runtime is free to treat them as being only their data, so they can be flattened into arrays or objects and passed by value rather than as references to heap objects. With this indication, the runtime can routinely give us a memory layout like this:

which is both flatter (no indirections) and denser (no headers) than the previous version. Save for these restrictions, inline classes can use most mechanisms available to classes: methods, constructors, fields, encapsulation, type variables, annotations, etc; the slogan is Codes like a class, works like an int. Inline types could equally be thought of as “faster classes” or “user-definable primitives”.
There are applications for inline types at every level. Many API abstractions, such as numerics, dates, cursors, and wrappers like Optional, are naturally inline types. Many data structures, such as HashMap, could use inline types in their implementations to improve efficiency. And language compilers can use them as a compilation target for features like built-in numeric types, tuples, or multiple return.
One of the early compromises of Java Generics is that generic type variables can only be instantiated with reference types, not primitive types. It has always been an irritant that one cannot generify over primitive types without boxing, which forces users to give up performance in order to get the benefit of abstraction or reuse. With the addition of inline types, this restriction becomes even more stifling; if we have the ability to create flattenable data types like our Point above, having an ArrayList<Point> not be backed by a flattened array of Point seems to defeat, well, the point.
Parametric polymorphism always entails tradeoffs between code footprint, abstraction, and specificity, and different languages have chosen different tradeoffs.
At one end of the spectrum, C++ creates a specialized class for each instantiation of a template, and different specializations have no typing relationship with each other. Such a heterogeneous translation provides a high degree of specificity, to the point where expressions such as a+b can be interpreted relative to the behavior of + on the instantiated types of a and b, but entails a large code footprint as well as a loss of abstraction – there is no type that is the equivalent of Foo<?> in Java.
At the other end, we have Java’s current erased implementation which produces one class for all reference instantiations and no support for primitive instantiations. Such a homogeneous translation yields a high degree of reuse, since there is only one class and one object layout for all reference instantiations. The restriction that we can only range over reference types, not primitives, has its roots in the bytecode set of the JVM, which uses different bytecodes for operations on reference types vs primitive types.
While most developers have a certain degree of distaste for erasure, this approach has a powerful advantage that we could not have gotten any other way: gradual migration compatibility. This is the ability to compatibly evolve a class from non-generic to generic, without breaking existing sources or binary class files, and leaving clients and subclasses with the flexibility to migrate immediately, later, or never. Offering users generics, but at the cost of throwing away all their libraries, would have been a bad trade in 2004, when Java already had a large and vibrant installed base (and would be a worse trade today.)
Our goal today is even more ambitious than it was in 2004: to extend generics so that we can instantiate them over primitives and inline classes, with specialized (heterogeneous) layouts, while retaining gradual migration capability. (Further, migration compatibility in the abstract is not enough; we want to actually migrate the libraries we have, including Collections and Streams.)
Project Valhalla has ambitious goals, and its intrusion is both deep and broad, affecting the classfile format, VM, language, and libraries. Over the past six years, we have done several prototypes, each aimed at deepening our understanding of different aspects of the problem.
Our first three prototypes explored the challenges of generics specialized to primtives, and worked by bytecode rewriting. The first (“Model 1”) was primarily aimed at the mechanics of specialization, and identifying what type behavior needed to be retained by the compiler and acted on by the specializer. The second (“Model 2”) explored how we might represent wildcards (and by extension, bridge methods) in a specializable generic model, and started to look at the challenges of migrating our existing libraries. The third (“Model 3”) consolidated what we’d learned, building a sensible classfile format that could be used to represent specialized generics. (For a brief tour of some of the challenges and lessons learned from each of these experiments, see this talk (slides here).
The results of these experiments were a mixed bag. On the one hand, it worked – it was possible to write specializable generic classes and run them on an only-slightly-hacked JVM. On the other hand, roadblocks abounded; existing classes were full of assumptions that were going to make them hard to migrate, and there were a number of issues for which we did not yet have a good answer.
We then attacked the problem from the other direction, with the “Minimal Value Types” prototype, whose goal was to prove that we could implement flat and dense layouts in the VM.
The turning point for Valhalla came with the most recent prototype, dubbed “L World” (because it lets inline classes share the L carrier with object references.) In our early explorations, we assumed a VM model where inlines were more like primitives – with separate type descriptors, bytecodes and top types – because it seemed too daunting to unify references and inlines under one set of type descriptors, bytecodes, and types. L-world attempted this unification, and (somewhat to our surprise) managed to do so without significant compromises. And the unification of types and descriptors provided by L-world addressed a significant number of the challenges we encountered in the early rounds of prototypes.
We intend to divide delivery of Project Valhalla into two broad phases: inline classes, and specialized generics. (These may be further divided into delivery milestones.) The first phase will focus on support for inline classes in the Java language and virtual machine; parts 2, 3, and 4 of this document describe this phase. This phase will also lay the groundwork for the use of inline classes in the JDK, and even migrating some existing value-based classes (such as Optional or LocalDateTime) to be inline classes.
The second phase will focus on generics, extending the generic type system to support instantiation with inline classes (which will include primitives), and extending the JVM to support specialized layouts.