1. Summary
We explored the potential benefits of having YIELD instruction implemented for Java.
YIELD instruction on ARM may be considered similar to x86 PAUSE.
It makes sense to add support for this instruction in JVM as Thread.onSpinWait() and SpinPause. This can be done even though this instruction is implemented as NOP in some CPUs.
2. Background
Intel implemented PAUSE instruction and benefits from power and performance improvements provided by this instruction. In older Intel processors this instruction took ~10 cycles, while on Skylake it’s up to 140 cycles. A similar instruction on ARMv8, YIELD may provide benefits when used properly.
3. HotSpot
There are few places in HotSpot where spin locks matter:
-
Thread.onSpinWait() JEP Spin-Wait Hints (JDK-8147832, discussion)
-
Implemented as a special intrinsic, PAUSE on x86, no-op for others.
-
As of JDK 9, this is used in StampedLock, Phaser, SynchronousQueue classes. It is likely it will be used more going forward.
-
-
SpinPause
-
Extern, may be defined in .s files src/os_cpu/linux_arm/vm/linux_arm_64.s – YIELD instruction for ARM64 OpenJDK port, not implemented in AARCH64 OpenJDK port. src/os_cpu/linux_x86/vm/linux_x86_64.s - REP; NOP = PAUSE
-
Synchronized (src/share/vm/runtime/objectMonitor.cpp)
-
Safepoints (src/share/vm/runtime/safepoint.cpp)
-
Using SEV/WFE instructions for spin waits in java is tricky because it may require SEV for all shared state writes, and locking logic assumes thread to stay on CPU for short time and then possibly be parked.
4. YIELD/PAUSE instruction use in other software
YIELD (ARM) and PAUSE (x86) are used in other software besides Java. To name some:
5. YIELD/PAUSE in Java/JVM - performance and power considerations
5.1. Thread.onSpinWait() intrinsic
Thread.onSpinWait() method was added in JDK 9 by Azul (JEP Spin-Wait Hints) that implemented it as PAUSE instruction on x86 HW. This is now used in some java classes (StampedLock, Phaser, SynchronousQueue) widely used in conventional Java software.
Two sets of benchmarks were used to compare Thread.onSpinWait() performance on Cavium ThunderX and Raspberry Pi 3.
-
The first one is a benchmark developed by Gil Tene - a set of benchmarks for original Spin-Wait Hints JEP
-
The second one is a JMH benchmark that was developed by BellSoft to microbenchmark the same intrinsic and gain additional information.
5.1.1. Linux x86-64 results
To verify our results for ARM and give them some background here are also some measurements on Intel i5.
Gil benchmarks
Results are much better with hyper-theading on same core but to compare it with HW we had it made sense to bind threads to different cores in the same package. Results are presented for this case though we also measured other cases too.
SpinWaitTest |
|
Latency, 100% |
|

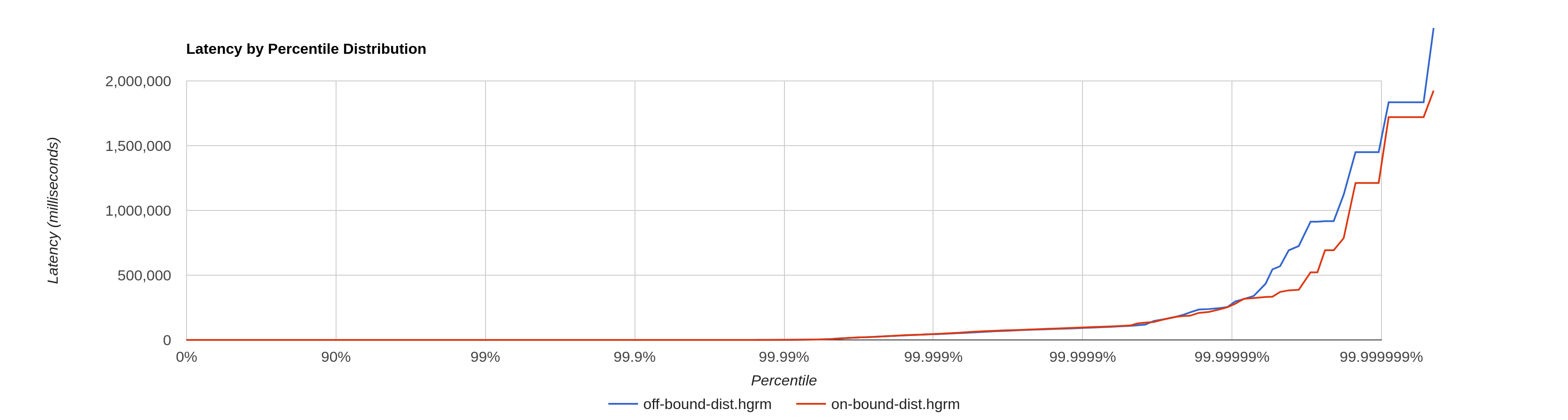
| Intrinsic is off {-XX:+UnlockDiagnosticVMOptions -XX:DisableIntrinsic=_onSpinWait} | Intrinsic is on |
|---|---|
#[Mean = 122.32, StdDeviation = 402.79] #[Max = 2408447.00, Total count = 200000000] #[Buckets = 35, SubBuckets = 256] # duration = 30342934158 # duration (ns) per round trip op = 151.71467079 # round trip ops/sec = 6591320 # 50%'ile: 121ns # 90%'ile: 130ns # 99%'ile: 144ns # 99.9%'ile: 191ns |
#[Mean = 106.27, StdDeviation = 365.33] #[Max = 1925119.00, Total count = 200000000] #[Buckets = 35, SubBuckets = 256] # duration = 27006943978 # duration (ns) per round trip op = 135.03471989 # round trip ops/sec = 7405502 # 50%'ile: 103ns # 90%'ile: 116ns # 99%'ile: 136ns # 99.9%'ile: 184ns |
Outcome of results analysis: ~20% lower latency is observed with PAUSE instruction for Thread.opSpinWait() on x86 when intrinsic is on.
BellSoft SpinWaitBench JMH benchmark
SpinWaitBench.java — 2 threads volatile ping-pong similar to Gil’s approach
SpinWaitNoAuxBench.java — slightly less harness work per operation
SpinWaitOpBench.java — calculates cost of Thread.onSpinWait() and infra cost
SpinWaitBench
Throughput in ops/us, #/op
| Intrinsic Off {-XX:+UnlockDiagnosticVMOptions -XX:DisableIntrinsic=_onSpinWait} | Intrinsic On {} |
|---|---|
Benchmark Score Error SpinWaitBench.pong 20.108 ± 0.560 :L1-dcache-load-misses 3.863 ± 0.704 :L1-dcache-loads 200.545 ± 36.993 :L1-dcache-store-misses 0.010 ± 0.027 :L1-dcache-stores 2.664 ± 0.627 :L1-icache-load-misses 0.042 ± 0.047 :LLC-loads 1.709 ± 2.007 :LLC-stores 0.993 ± 0.238 :branch-misses 0.088 ± 0.026 :branches 131.968 ± 23.358 :consume 10.054 ± 0.280 :cycles 308.754 ± 64.203 :dTLB-load-misses 0.002 ± 0.002 :dTLB-loads 200.576 ± 39.358 :dTLB-store-misses ≈ 10⁻⁴ :dTLB-stores 2.557 ± 0.347 :iTLB-load-misses 0.001 ± 0.003 :iTLB-loads 0.001 ± 0.005 :instructions 530.368 ± 91.808 :produce 10.054 ± 0.280 :stalled-cycles-frontend 156.833 ± 39.406 :totalSpins 613.655 ± 11.808 :CPI 0.582 ± 0.056 |
Benchmark Score Error SpinWaitBench.pong 22.696 ± 1.004 :L1-dcache-load-misses 2.125 ± 2.344 :L1-dcache-loads 22.649 ± 5.490 :L1-dcache-store-misses 0.008 ± 0.026 :L1-dcache-stores 2.594 ± 0.868 :L1-icache-load-misses 0.026 ± 0.050 :LLC-loads 1.133 ± 2.134 :LLC-stores 0.975 ± 0.220 :branch-misses 0.455 ± 0.906 :branches 14.141 ± 3.955 :consume 11.348 ± 0.501 :cycles 271.357 ± 97.363 :dTLB-load-misses 0.002 ± 0.006 :dTLB-loads 22.711 ± 7.788 :dTLB-store-misses ≈ 10⁻⁴ :dTLB-stores 2.674 ± 0.669 :iTLB-load-misses 0.001 ± 0.001 :iTLB-loads 0.001 ± 0.003 :instructions 67.516 ± 18.550 :produce 11.348 ± 0.502 :stalled-cycles-frontend 230.792 ± 79.629 :totalSpins 61.882 ± 1.373 :CPI 4.018 ± 0.477 |
Outcome of results analysis: 10x less totalSpins, cache loads, dtlb loads, instructions. More stalled frontend. Better latency, same core is even better (thrpt, 30x spins). SpinWaitNoAuxBench shows more noise.
SpinWaitOpBench
| Intrinsic off {-XX:+UnlockDiagnosticVMOptions -XX:DisableIntrinsic=_onSpinWait} | Intrinsic on {} |
|---|---|
Benchmark Mode Cnt Score Error Units empty avgt 20 0.314 ± 0.002 ns/op :cycles avgt 4 1.016 ± 0.026 #/op :instructions avgt 4 4.975 ± 0.255 #/op |
Benchmark Mode Cnt Score Error Units empty avgt 20 0.313 ± 0.001 ns/op :cycles avgt 4 1.020 ± 0.037 #/op :instructions avgt 4 5.028 ± 0.251 #/op |
Benchmark Mode Cnt Score Error Units onSpinWait avgt 20 0.319 ± 0.006 ns/op :cycles avgt 4 1.029 ± 0.076 #/op :instructions avgt 4 5.033 ± 0.172 #/op |
Benchmark Mode Cnt Score Error Units onSpinWait avgt 20 5.215 ± 0.023 ns/op :cycles avgt 4 16.922 ± 0.840 #/op :instructions avgt 4 6.039 ± 0.306 #/op |
Outcome of results analysis: PAUSE length on i5-3320M is ~16 cycles.
Power consumption of the system is 18.3±1.5 W for both cases then the workload runs on single CPU, according to powerstat. This method is not very informative but we had no other good means to measure power.
5.1.2. Linux AArch64 results
To study the potential benefits of implementation of YIELD on ARMv8 a patch was developed for jdk10/hs that adds C1 and C2 intrinsic implementation for onSpinWait() as yield instruction.
Gil benchmarks on ThunderX
SpinWaitTest |
|
Latency, 99.9% |
|
Latency, 100% |
|


#[Mean = 219.41, StdDeviation = 193.52] #[Max = 2392063.00, Total count = 200000000] #[Buckets = 35, SubBuckets = 256] # duration = 65672330449 # duration (ns) per round trip op = 328.361652245 # round trip ops/sec = 3045422 # 50%'ile: 220ns # 90%'ile: 220ns # 99%'ile: 230ns # 99.9%'ile: 230ns
Outcome of results analysis: Same and high latency, e.g. for cores in same package.
SpinWaitBench JMH benchmark
Both on Raspberry Pi 3 and Cavium ThunderX and perf statistics show that the instruction is implemented as NOP.
On the other hand:
-
Average number of spins can be counted.
-
We may consider influence of doing less loads by adding a lot of NOPs into the body of the loop instead of 1 yield (32 for instance). With this amount of NOPs on Cavium threads are bound to cores in same package and the results are below
SpinWaitBench, throughput ops/us and #/op
Intrinsic Off |
Intrinsic On |
Benchmark Score Error SpinWaitBench.pong 15.780 ± 0.102 :CPI 1.498 ± 0.033 :L1-dcache-load-misses 1.016 ± 0.041 :L1-dcache-loads 81.948 ± 4.772 :L1-dcache-store-misses 0.022 ± 0.102 :L1-dcache-stores 1.640 ± 0.215 :L1-icache-load-misses 0.012 ± 0.039 :L1-icache-loads 142.277 ± 6.906 :branch-misses 1.036 ± 0.077 :branches 25.848 ± 1.335 :consume 7.893 ± 0.051 :cycles 256.317 ± 1.805 :dTLB-load-misses 0.006 ± 0.011 :dTLB-loads 82.002 ± 4.179 :dTLB-store-misses 0.002 ± 0.005 :dTLB-stores 1.631 ± 0.196 :iTLB-load-misses 0.002 ± 0.007 :instructions 171.083 ± 3.045 :produce 7.887 ± 0.052 :stalled-cycles-backend 126.831 ± 1.510 :stalled-cycles-frontend 10.720 ± 1.970 :totalSpins 140.333 ± 4.825 |
Benchmark Score Error SpinWaitBench.pong 14.876 ± 0.138 :CPI 1.058 ± 0.015 :L1-dcache-load-misses 1.017 ± 0.046 :L1-dcache-loads 23.534 ± 1.125 :L1-dcache-store-misses 0.020 ± 0.045 :L1-dcache-stores 1.627 ± 0.188 :L1-icache-load-misses 0.018 ± 0.031 :L1-icache-loads 109.518 ± 4.125 :branch-misses 1.098 ± 0.208 :branches 6.340 ± 0.460 :consume 7.438 ± 0.069 :cycles 270.067 ± 10.309 :dTLB-load-misses 0.009 ± 0.008 :dTLB-loads 23.588 ± 0.368 :dTLB-store-misses 0.002 ± 0.002 :dTLB-stores 1.674 ± 0.242 :iTLB-load-misses 0.002 ± 0.004 :instructions 255.178 ± 12.632 :produce 7.437 ± 0.068 :stalled-cycles-backend 109.726 ± 2.667 :stalled-cycles-frontend 14.605 ± 1.210 :totalSpins 37.567 ± 1.358 |
Outcome of results analysis: totalSpins decreased from 140 to 35 and throughput is the same. Similar results are expected with single yield instruction on hardrawe where it’s implemented for either SMT or temporal multithreading.
Throughput and measured latency in case of 48 ping-pong pairs on 96-core processor is about the same. Though runs with 32 NOPs have higher deviation (like 15±3 ops/us → 13±18 ops/us per pair).
SpinWaitOpBench
Intrinsic Off |
Intrinsic On |
Benchmark Mode Cnt Score Error Units empty avgt 20 1.508 ± 0.002 ns/op :cycles avgt 4 3.097 ± 0.287 #/op :instructions avgt 4 4.068 ± 0.306 #/op |
Benchmark Mode Cnt Score Error Units empty avgt 20 1.509 ± 0.002 ns/op :cycles avgt 4 3.101 ± 0.225 #/op :instructions avgt 4 4.016 ± 0.219 #/op |
Benchmark Mode Cnt Score Error Units onSpinWait avgt 20 1.509 ± 0.002 ns/op :cycles avgt 4 3.077 ± 0.221 #/op :instructions avgt 4 4.002 ± 0.186 #/op |
Benchmark Mode Cnt Score Error Units onSpinWait avgt 20 9.057 ± 0.018 ns/op :cycles avgt 4 18.814 ± 1.835 #/op :instructions avgt 4 36.407 ± 2.472 #/op |
Outcome of results analysis: intrinsic with 32 NOPs takes ~16 cycles.
5.2. SpinPause
YIELD can be used for synchronized and SpinPause in JVM very similar to Thread.onSpinWait() intrinsic. On x86, spin pause is also done with PAUSE instruction. Current implemetation of SpinPause in linux-aarch64 is an empty function. We made some sanity measurements to check SpinPause impelementation with yield and they show no regressions. But generally it is a good thing to check in any benchmarks.
6. Conclusions
-
We propose to add onSpinWait() intrinsic and SpinPause implementation in (Linux) AArch64 port with
yieldinstruction. -
It is harmless for CPUs that implement the instruction as NOP.
-
It should be benefitial for CPUs that have SMT or are able to partially shut down or pause for a while.
-
It may be considered to emit several
nopinstead ofyieldwhere latter works asnopto decrease memory pressure without loosing throughput.-
A concrete latency estimate for a potential implementation that should not cause any performance degradation for Java is around 16 cycles.
-