2019-08-23
Benchmarks
It’s always tricky to write microbenchmarks on Java for sorting algorithms (or any data structure modifications), because of we have to create new data structure (or copy golden copy) before each operation. Even if we successfully excluded preparation time from our measurement time (that is not always possible), it quite difficult to exclude preparation time from profile information. Besides, number of golden copies can’t really be large or randomized and may loose interesting scenarios. Other approach is used in this study. 'Salted' value is mixed with comparison operation and is changed after each sort operation (immediately and 'magically' provides unsorted array). The disadvantage of this approach is that sometimes it may produce data with quite different unsortness degree and thus large difference in time of sorting. That required a large amount repetitions to achieve desired convergence of average result.
The key goal of the study was comparing behavior of identical sorting algorithms on similar reference and inline classes. This implies that amount and sequence of compare operations is the same for both kinds of classes, the only difference is data moving. Inline classes requires more copying data (the whole value should be moved) vs references (only reference is moved). That is why benchmarks use as much as possible light-weight compare operation to reduce cost of compare in our study. Only data moving is targeted. In order to limit number of benchmarks to reasonable value our implemented compare operation follows the worst case memory access scenario it reads all fields of comparing class. Partial scenarios (only some fields are read) may be more commonly used, but they works faster (or with the same speed) as worst case scenario.
Two stable sorting algorithms were analyzed. Classical MergeSort and TimSort (default sort algorithm from Java classlib). Manual specialization of each algorithm was implemented for inline classes. Besides straightforward inline classes sorting, both algorithms were implemented in 'indexed' version: sort array of 'int' indices and copy values to result after. Two algorithms were checked to convert unsorted array by sorted indices. The first uses auxiliary array and copy values from one to another. The second performs permutation in place and don’t need additional allocation. The second worked significantly slower than the first and was excluded.
It was analyzed classes of 8, 16, 24, 32, and 64 bytes of size (2,4,6,8, and 16 int fields).
Benchmarked arrays have sizes: 400, 4000, 40000, 400000, and 4000000. That numbers were chosen to approximately fit working set into L1 cache (400), L2 (4000), L3 (40000), slightly large than L3 (400000), and significantly larger than L3 (4000000). That is true for classes 8..32 bytes size. 64 bytes class slightly out of desired cache sizes.
The goal was to look into current general picture. None of algorithmic tuning was performed. Also, it is knows, it may be produced some inefficiency in generated code for inline types, that case also was not analyzed.
Results by size of class
Sort of 8 bytes classes
| 400 | 4000 | 40000 | 400000 | 4000000 | ||
|---|---|---|---|---|---|---|
ref MergeSort |
|
|
|
|
|
|
val MergeSort |
|
|
|
|
|
|
val MergeSort indexed |
|
|
|
|
|
|
ref TimSort |
|
|
|
|
|
|
val TimSort |
|
|
|
|
|
|
val TimSort indexed |
|
|
|
|
|
|
|
||||||
Results from the table above are converted into relative chart where reference TimSort results (as defauld JDK algorithm) is considered as 100%:

Sort of 16 bytes classes
| 400 | 4000 | 40000 | 400000 | 4000000 | ||
|---|---|---|---|---|---|---|
ref MergeSort |
|
|
|
|
|
|
val MergeSort |
|
|
|
|
|
|
val MergeSort indexed |
|
|
|
|
|
|
ref TimSort |
|
|
|
|
|
|
val TimSort |
|
|
|
|
|
|
val TimSort indexed |
|
|
|
|
|
|
|
||||||
Relative performance:

Sort of 24 bytes classes
| 400 | 4000 | 40000 | 400000 | 4000000 | ||
|---|---|---|---|---|---|---|
ref MergeSort |
|
|
|
|
|
|
val MergeSort |
|
|
|
|
|
|
val MergeSort indexed |
|
|
|
|
|
|
ref TimSort |
|
|
|
|
|
|
val TimSort |
|
|
|
|
|
|
val TimSort indexed |
|
|
|
|
|
|
|
||||||
Relative performance:

Sort of 32 bytes classes
| 400 | 4000 | 40000 | 400000 | 4000000 | ||
|---|---|---|---|---|---|---|
ref MergeSort |
|
|
|
|
|
|
val MergeSort |
|
|
|
|
|
|
val MergeSort indexed |
|
|
|
|
|
|
ref TimSort |
|
|
|
|
|
|
val TimSort |
|
|
|
|
|
|
val TimSort indexed |
|
|
|
|
|
|
|
||||||
Relative performance:

Sort of 64 bytes classes
| 400 | 4000 | 40000 | 400000 | 4000000 | ||
|---|---|---|---|---|---|---|
ref MergeSort |
|
|
|
|
|
|
val MergeSort |
|
|
|
|
|
|
val MergeSort indexed |
|
|
|
|
|
|
ref TimSort |
|
|
|
|
|
|
val TimSort |
|
|
|
|
|
|
val TimSort indexed |
|
|
|
|
|
|
|
||||||
Relative performance:
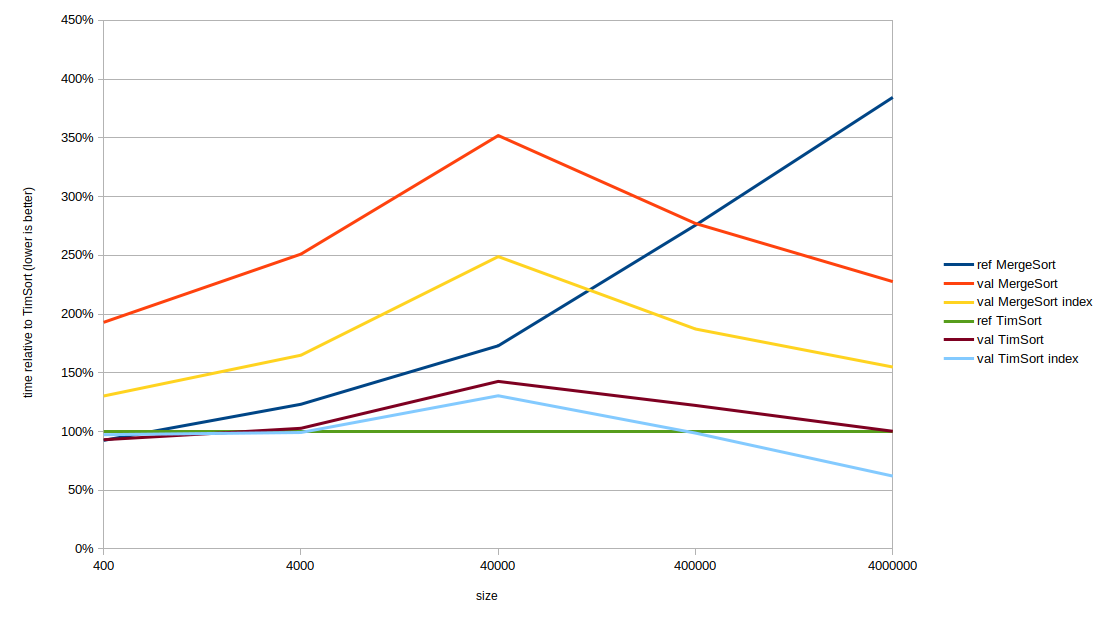
Results by length of array


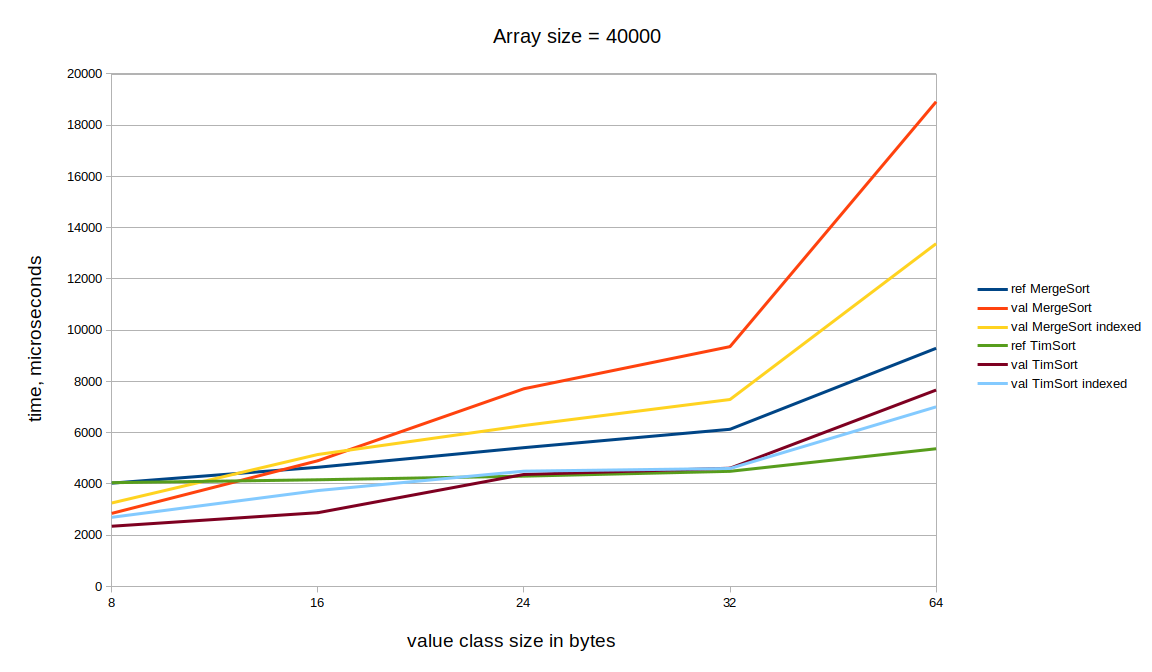
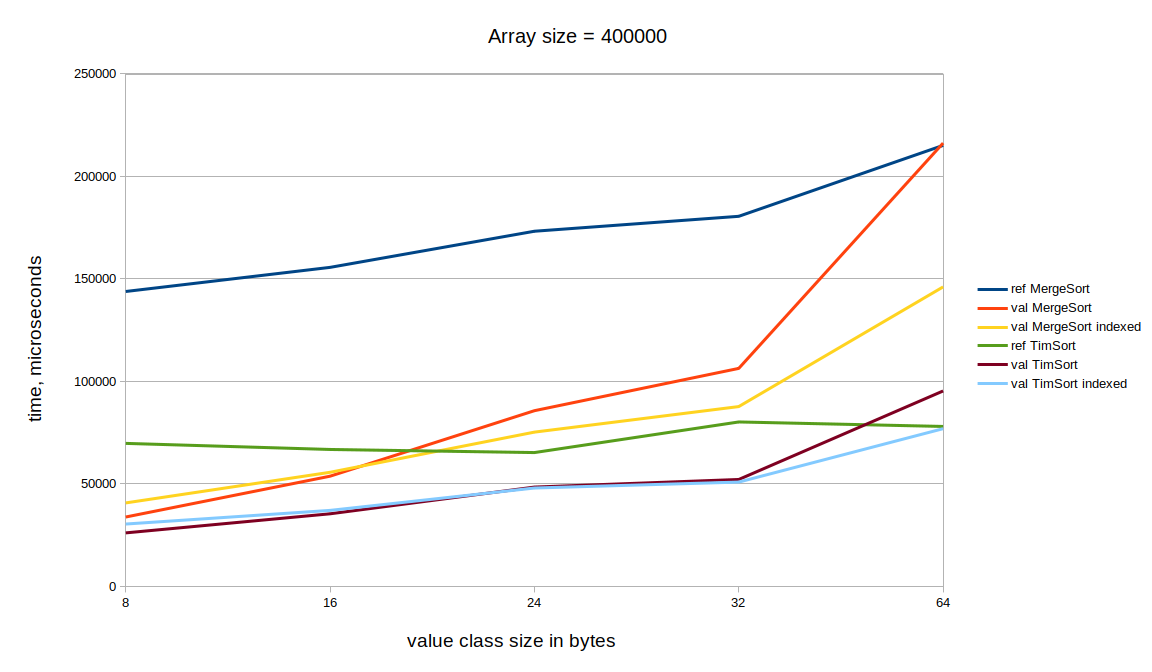
Memory consumption
Inline types sorting has signicant larger auxiliary memory allocation. Just as example for array size = 400.
| 8 | 16 | 24 | 32 | 64 | ||
|---|---|---|---|---|---|---|
ref MergeSort |
|
|
|
|
|
|
val MergeSort |
|
|
|
|
|
|
val MergeSort indexed |
|
|
|
|
|
|
ref TimSort |
|
|
|
|
|
|
val TimSort |
|
|
|
|
|
|
val TimSort indexed |
|
|
|
|
|
|
|
||||||
| 8 | 16 | 24 | 32 | 64 | ||
|---|---|---|---|---|---|---|
ref MergeSort |
|
|
|
|
|
|
val MergeSort |
|
|
|
|
|
|
val MergeSort indexed |
|
|
|
|
|
|
val TimSort |
|
|
|
|
|
|
val TimSort indexed |
|
|
|
|
|
|
|
||||||
In general, extra allocations for reference sorting are within 3% - 20% of original data set size. Inline types extra allocations are within 100%-200%. (which is not surprising).
Conclusion
-
for small class sizes or small array sizes value type sort is faster than reference and even faster than indexed value type sort
-
for larger class sizes and larger array sizes indexed sort is more preferable
-
reference sort wins only in small amout of cases
So even for some data modification algorithms inline types win over references due to data locality.
The case where reference types are fastest here is the case of 400000 elements array. "Fit to L3 case". The reason of that is large extra memory allocations for inline types, our data set became slightly larger than L3 cache.
|
Note
|
It’s crucial to get specialized codegeneration for each inline class used for sorting. Without specialization generic objectified version will kill all benefits obtained by data locality. Right now C2 is able to provide such specialization only with methods inline. TimSort code is large enough not be inlined. Taking this into consideration indexed sort looks more prefferable, because of inline types are localized to relatively small top method. |